|
|
személyes honlap
|
||
| Tartalmilag utoljára módosítva: |
2004. augusztus |
||
|
Nem végleges! |
|
||||||||||||||||||||||||||||||||||||||||||||||
|
/ Sidló Csaba, ELTE / |
||||||||||||||||||||||||||||||||||||||||||||||
|
||||||||||||||||||||||||||||||||||||||||||||||
| 1. Bevezetés | ||||||||||||||||||||||||||||||||||||||||||||||
| 1.1. Vállalati környezet | ||||||||||||||||||||||||||||||||||||||||||||||
| 1.2. Vállalati adathalmazok, döntéstámogatás | ||||||||||||||||||||||||||||||||||||||||||||||
| 1.3. Információszükségleti hierarchia | ||||||||||||||||||||||||||||||||||||||||||||||
| 2. Vállalatirányítási és döntéstámogató rendszerek evolúciója | ||||||||||||||||||||||||||||||||||||||||||||||
| 3. Az adattárház koncepció | ||||||||||||||||||||||||||||||||||||||||||||||
| 3.1. Az adattárház (data warehouse) fogalma | ||||||||||||||||||||||||||||||||||||||||||||||
| 3.1.1. Néhány adattárház definíció | ||||||||||||||||||||||||||||||||||||||||||||||
| 3.1.2. Inmon definíciója | ||||||||||||||||||||||||||||||||||||||||||||||
| 3.2. A "Data Warehousing" fogalma | ||||||||||||||||||||||||||||||||||||||||||||||
| 3.3. A "Business Intelligence" (BI) fogalma | ||||||||||||||||||||||||||||||||||||||||||||||
| 4. Az adattárház architekrúra | ||||||||||||||||||||||||||||||||||||||||||||||
| 4.1. Operational Data Store-tól az Extraprise Data Warehouse-ig | ||||||||||||||||||||||||||||||||||||||||||||||
| 4.2. Adattárház architektúrák | ||||||||||||||||||||||||||||||||||||||||||||||
| 5. OLTP és OLAP rendszerek | ||||||||||||||||||||||||||||||||||||||||||||||
| 5.1. OLTP rendszerek | ||||||||||||||||||||||||||||||||||||||||||||||
| 5.2. Új követelmények - OLAP rendszerek | ||||||||||||||||||||||||||||||||||||||||||||||
| 5.3. OLTP - OLAP renszerek összehasonlítása | ||||||||||||||||||||||||||||||||||||||||||||||
| 6. Adatmodellezés | ||||||||||||||||||||||||||||||||||||||||||||||
| 6.1. Adatsémák a tranzakciófeldolgozó rendszerektől az OLAP alkalmazásokig | ||||||||||||||||||||||||||||||||||||||||||||||
| 6.2. Tranzakciós rendszerek adatmodelljei - operációs séma | ||||||||||||||||||||||||||||||||||||||||||||||
| 6.3. Szemantikai réteg - felhasználói multidimenzionális adatfogalom | ||||||||||||||||||||||||||||||||||||||||||||||
| 6.3.1. Alapfogalmak | ||||||||||||||||||||||||||||||||||||||||||||||
| 6.3.2. Az adatkockák megjelenítése, kezelése a felhasználói felületen | ||||||||||||||||||||||||||||||||||||||||||||||
| 6.3.3. Analízisoperátorok | ||||||||||||||||||||||||||||||||||||||||||||||
| 6.3.4. A modell formalizált leírása | ||||||||||||||||||||||||||||||||||||||||||||||
| 6.4. Logikai réteg - adatbázis (belső) sémák | ||||||||||||||||||||||||||||||||||||||||||||||
| 7. MOLAP architektúrák | ||||||||||||||||||||||||||||||||||||||||||||||
| 7.1. Adatstruktúrák | ||||||||||||||||||||||||||||||||||||||||||||||
| 7.2. A többdimenziós tömb tárolás | ||||||||||||||||||||||||||||||||||||||||||||||
| 7.3. Ritka mátrix kezelés | ||||||||||||||||||||||||||||||||||||||||||||||
| 7.4. A multidimenzionális tárolás korlátai | ||||||||||||||||||||||||||||||||||||||||||||||
| 7.5. MOLAP termékek | ||||||||||||||||||||||||||||||||||||||||||||||
| 8. ROLAP architektúrák | ||||||||||||||||||||||||||||||||||||||||||||||
| 8.1. Relációs adattárház séma tervezésének 4 lépéses folyamata | ||||||||||||||||||||||||||||||||||||||||||||||
| 8.2. Csillagséma (star schema) | ||||||||||||||||||||||||||||||||||||||||||||||
| 8.3. Hópehely séma (snowflake schema) | ||||||||||||||||||||||||||||||||||||||||||||||
| 8.4. Konszolidált csillagséma | ||||||||||||||||||||||||||||||||||||||||||||||
| 8.7. ROLAP teljesítmény javítása | ||||||||||||||||||||||||||||||||||||||||||||||
| 8.7.1. Denormalizáció | ||||||||||||||||||||||||||||||||||||||||||||||
| 8.7.2. Aggregáció | ||||||||||||||||||||||||||||||||||||||||||||||
| 8.7.3. Particionálás | ||||||||||||||||||||||||||||||||||||||||||||||
| 9. HOLAP architektúrák | ||||||||||||||||||||||||||||||||||||||||||||||
| 10. Adattárház komponensek | ||||||||||||||||||||||||||||||||||||||||||||||
| 10.1. Az adatok kinyerése és betöltése az adattárházba | ||||||||||||||||||||||||||||||||||||||||||||||
| 10.2. Adatszolgáltatás az alkalmazások felé (OLAP Tools) | ||||||||||||||||||||||||||||||||||||||||||||||
| 10.3. Alkalmazások | ||||||||||||||||||||||||||||||||||||||||||||||
| 10.4.. Felügyelet, adminisztráció és metaadat-kezelés | ||||||||||||||||||||||||||||||||||||||||||||||
| 11. Az adattárház megoldás bevezetésének folyamata, az adattárház-project | ||||||||||||||||||||||||||||||||||||||||||||||
| 12. Kurrenskutatási területek | ||||||||||||||||||||||||||||||||||||||||||||||
| 12.1. Aggregáció | ||||||||||||||||||||||||||||||||||||||||||||||
| 12.2. Indexek | ||||||||||||||||||||||||||||||||||||||||||||||
| 12.3. Induktív adatbázisok | ||||||||||||||||||||||||||||||||||||||||||||||
| 12.4. Lekérdezés optimalizálás | ||||||||||||||||||||||||||||||||||||||||||||||
| 12.5. SQL bővítés | ||||||||||||||||||||||||||||||||||||||||||||||
| 12.6. Formális adatmodellek | ||||||||||||||||||||||||||||||||||||||||||||||
| 12.7. Elosztott adattárházak | ||||||||||||||||||||||||||||||||||||||||||||||
| 12.8. Metaadat kezelés | ||||||||||||||||||||||||||||||||||||||||||||||
| 12.9. Weblog-elemző Clickstream adattárházak | ||||||||||||||||||||||||||||||||||||||||||||||
| 13. Az adattárház piac és szereplői | ||||||||||||||||||||||||||||||||||||||||||||||
Irodalom |
||||||||||||||||||||||||||||||||||||||||||||||
|
||||||||||||||||||||||||||||||||||||||||||||||
|
Data Warehouse, adattárház: az információtechnológia
viszonylag frissen önálló életre kelt ága, kevesebb mint egy évtizedes
múltra visszatekintő területe. Rohamléptekkel, egyszerre több irányzat
mentén fejlődő, már bizonyított és kiforratlan technológiák halmaza, kevés
elismert szabvánnyal, rengeteg kapcsolódó termékkel és szolgáltatással, sok
kis, néhány nagyobb piaci szereplővel, valamint nem utolsósorban meggyőző
piaci adatokkal. |
||||||||||||||||||||||||||||||||||||||||||||||
1.1. Vállalati környezet |
||||||||||||||||||||||||||||||||||||||||||||||
|
A következőkben megvizsgáljuk az adattárház technológiák alkalmazásának mozgatórugóit, felhasználói körét, alkalmazásának környezetét. Induljunk ki ehhez először tetszőleges vállalatból valamely gazdasági tevékenységgel, versenyhelyzetben a többi hasonló vállalattal. A piaci kihívásokra, a dinamikusan változó gazdasági környezetre az adott vállalat lehetőségei szerint reagál, rövid- közép- és stratégiai céljainak megfelelően. Ezeket a reakciókat, lépéseket (akárcsak a célokat) a vállalat vezetése határozza meg. A vállalat vezetésének folyamata felfogható tehát (az egyik elterjedt vállalatvezetési modell szerint) döntéshozatalként, döntések sorozatainak meghozatalaként. A vállalat eredményessége a reakciók, vagyis a döntések minőségén, sebességén múlik. Érthető tehát, hogy a vállalatok (az egyébként mind kritikusabb) kihívásokra válaszképp mindinkább szeretnék ezeket a döntéseket és velük együtt a vállalat vezetőit, a döntéshozókat eszközökkel, módszerekkel támogatni, naprakész, jól használható információval ellátni. Egy adattárház megoldás megvalósításával ilyen, döntések információs hátterét biztosító adat- és tudásbázishoz juthatunk. |
||||||||||||||||||||||||||||||||||||||||||||||
1.2. Vállalati adathalmazok, döntéstámogatás |
||||||||||||||||||||||||||||||||||||||||||||||
|
A vállalat működéséhez elengedhetetlenül szükségesek
bizonyos adathalmazok, nyilvántartások. Ilyenek pl. a könyvelések, a
számlázások, személyi nyilvántartások, stb. Ezek az adatok valamilyen
formában (elektronikusan vagy akár papíron) mindig
rendelkezésre állnak, de amellett, hogy a működéshez szükségesek, önmagukban
még nem feltétlenül segítik elő a megfelelő
döntéshozatalt. A megfelelő információk előállítását, szolgáltatását
célozza meg többek közt a controlling (v. kontrolling) mint közgazdasági
irányvonal, részfeladatként a vállalatirányítás folyamatának
racionalizálásában, megfelelő információs alapra helyezésében.
Másrészről, ugyancsak ezekre a célokra, csak információs technológiák
irányából közelítve ezért jelentek meg a különböző döntéstámogató rendszerek
(Decision
Support Systems, DSS), melyek az információ-ellátás informatikai hátterét
hivatottak biztosítani. |
||||||||||||||||||||||||||||||||||||||||||||||
1.3. Információszükségleti hierarchia |
||||||||||||||||||||||||||||||||||||||||||||||
|
1943-ban Maslow angol szociológus megalkotta az emberi
szükségletek hiearchiájának elméletét. Ez egy igen egyszerű elmélet, amely
szerint az emeri szükségleteket alapvetőtől az önmegvalósító tevékenységek
igényéig sorba rendezhetjük. A sor jellemzője, hogy a következő szintű
igények csak akkor jelentkeznek, ha a hierarchiában alatta lévőt már kielégítettük. Így először az
alapvető fizikai szükségleteknek megfelelően eszünk, iszunk, ezután foglalkozhatunk
a biztonságunkkal, ha ez is teljesül, sorra jönnek a szociális, majd az
önkiteljesítést szolgáló öncélú igények. |
||||||||||||||||||||||||||||||||||||||||||||||
|
|
||||||||||||||||||||||||||||||||||||||||||||||
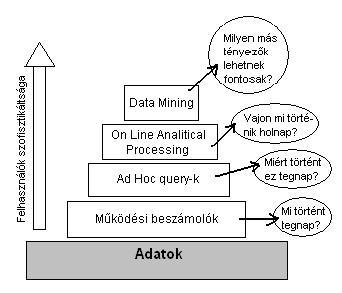
|
1.ábra: Vállalati adatszükségleti hierarchia |
||||||||||||||||||||||||||||||||||||||||||||||
|
A piramis alján foglalnak helyet a vállalat működéséhez feltétlenül szükséges adatok. (pl. számlák, szállítások adatai, megrendelések, gyártási adatok, stb.) A feljebb mind bonyolultabbá és összetettebbekké váló kérdésekre csak egyre összetettebb módszerekkel, technológiákkal lehetséges választ adni. Tulajdonképp a felső két-három szint stabil információszolgáltató háttereként születtek meg az adattárház technológiák. |
||||||||||||||||||||||||||||||||||||||||||||||
|
||||||||||||||||||||||||||||||||||||||||||||||
|
60-as évek: Executive Information Systems (EIS)
80-as évek: Management Information Systems (MIS)
1992: W.H.Inmon bevezeti az adattárház fogalmát úttörő munkájával
1993: OLAP célok, követelményrendszer bevezetése (E.F.Codd)
|
||||||||||||||||||||||||||||||||||||||||||||||
|
||||||||||||||||||||||||||||||||||||||||||||||
3.1. Az adattárház (data warehouse) fogalma |
||||||||||||||||||||||||||||||||||||||||||||||
|
Próbálkozzunk meg az adattárház definíciójával. Bár mára a kifejezés értelmezésében viszonylag nagy az egyetértés, kisebb értelmezésbeli, nézőpontbeli különbségek még mindig jelen vannak. Nézzük először, hogy az adattárház elmélet két evangelistájának mondott űttörőnk Ralph Kimball és Bill Inmon hogyan is fogja meg a fogalmat: (Az idézett könyvek ([1][2]) egyébként egyelőre kiállták az idő próbáját, és még ma is a két alapműként tartják számon a témában - 1996 óta, ami persze nem nagy idő.) |
||||||||||||||||||||||||||||||||||||||||||||||
3.1.1. Néhány adattárház definíció |
||||||||||||||||||||||||||||||||||||||||||||||
|
Idézet Ralph Kimballtól: Data Warehouse: "The conglomeration of
an organization's data warehouse staging and presentation areas, where
operational data is specifically structured for query and analysis
performance and ease-of-use." [2] Az adattárház fogalma itt tehát egy adott szervezet azon
adatgyűjtő és szolgáltató részeit foglalja magában, ahol a működési adatokat
újrastrukturálják riportkészítési, jó teljesítményű és egyszerűen kezelhető
elemzésekhez. Kimball ezen definícióját főleg azért szokták kedvelni és idézni, mert sok
mindent nem határoz meg, pl. az adattárház nem feltétlenül döntéstámogatási
célú. |
||||||||||||||||||||||||||||||||||||||||||||||
3.1.2. Inmon definíciója |
||||||||||||||||||||||||||||||||||||||||||||||
|
Kimball az adattárházat máshol egyszerűbben a
vállalati tranzakciós adatok egy speciális, elemzési és
beszámoló-készítési célra átstrukturált változatának tartja, egy
speciális adatbázisnak. Ez az adatbázisként való megközelítés már csak
egy pontatlanabb változata Bill Inmon általánosan elfogadott és az
irodalomban leginkább idézett definíciójának: Nézzük végig az említett (elemzési céloknak alárendelt) jellemzőket!
|
||||||||||||||||||||||||||||||||||||||||||||||
3.2. A "Data Warehousing" fogalma |
||||||||||||||||||||||||||||||||||||||||||||||
|
Data Warehousing alatt értjük adott szervezet
adatainak adattárház eszközzel való kezelésének folyamatát, az adatok
keletkezésének helyétől indulva egészen az elemzési célú megjelenítésig.
|
||||||||||||||||||||||||||||||||||||||||||||||
3.3. A "Business Intelligence" (BI) fogalma |
||||||||||||||||||||||||||||||||||||||||||||||
|
A Business Intelligence (BI), üzleti intelligencia fogalámát Howard Dresner (Gartner Group) definiálta 1989-ben, azóta általánosan elfogadott fogalommá vált. Olyan módszerek, fogalmak halmazát jelenti, melyek a döntéshozás folyamatát javítják adatok és ún. tényalapú rendszerek használatával. A "tényalapú rendszer" a következő alrendszereket foglalja magába:
Az üzleti intelligencia fogalmát gyakran említik együtt az adattárházak fogalmával, mivel az lefedheti ezen részrendszereket, valamint kiszolgálhat ilyen rendszereket. Leginkább azonban tekinthetjük az adattárház megoldásokat az üzleti intelligencia megoldások egy szeletének. |
||||||||||||||||||||||||||||||||||||||||||||||
|
||||||||||||||||||||||||||||||||||||||||||||||
4.1. Operational Data Store-tól az Extraprise Data Warehouse-ig |
||||||||||||||||||||||||||||||||||||||||||||||
|
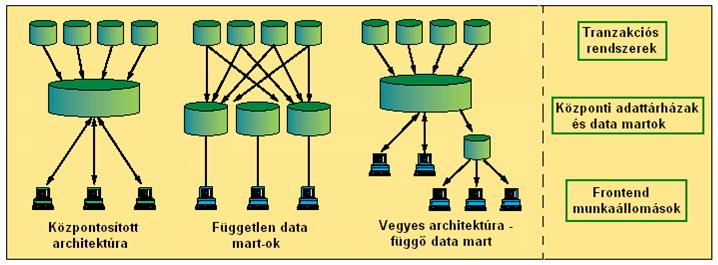
Az adattárház megoldás mérete és célja szerint széles skálán mozog, ezekre szokás külön elnevezéseket használni. Data mart (adatpiac): A data mart egy lokális, a vállalat
valamely felhasználói csoportja, szakterülete számára készült, konkrét
feladatot ellátó, kisebb adattároló és analizáló egységet jelent, amely már
önmagában is adattárház funkciókat láthat el. |
||||||||||||||||||||||||||||||||||||||||||||||
4.2. Adattárház architektúrák |
||||||||||||||||||||||||||||||||||||||||||||||
|
Ebben a pontban kicsit részletesebben foglalkozunk az
adatok 3.2
pontban (Data Warehousing fogalma) leírt háromlépcsős útjának
megvalósításával. Az adattárház felépítését, építőelemeit tekintve egy
kliens-szerver rendszer. Jelenti ez azt, hogy a felhasználó egy kliensen
keresztül kiszolgáló, kiszolgálók szolgáltatásait használja. A
munkamegosztást tekintve a megvalósítások széles skálán mozognak, kezdve az
egy gépen futó kliens-szerver párostól a sok gépre, különböző stratégiák
szerint elosztott kliens-szerver rendszerekig. Ezeknek nézzük most meg
alapvető változatait. |
||||||||||||||||||||||||||||||||||||||||||||||
|
|
||||||||||||||||||||||||||||||||||||||||||||||
|
2.ábra: Architektúra típusok |
||||||||||||||||||||||||||||||||||||||||||||||
|
||||||||||||||||||||||||||||||||||||||||||||||
| 5.1. OLTP rendszerek | ||||||||||||||||||||||||||||||||||||||||||||||
|
OLTP: On Line Transaction Processing, azaz online tranzakciófeldolgozás. OLTP rendszerek alatt értjük általában az adatbázis rendszerek hagyományos alkalmazásait. Ide sorolhatók pl. a raktárnyilvántartások, szállítási nyilvántartások, könyvtár kölcsönzési adatbázisa, számlanyilvántartó rendszerek, filmkatalógusok és így tovább. Központi fogalmuk a tranzakció végrehajtás, a következő értelemben: az adatbázis objektumainak állapotát a felhasználók konkurens módon végrehajtott és egyenkénti, kis tranzakciók gyakori végrehajtásával módosítják és kérdezik le. |
||||||||||||||||||||||||||||||||||||||||||||||
5.2. Új követelmények - OLAP rendszerek |
||||||||||||||||||||||||||||||||||||||||||||||
|
OLAP: On Line Analitical Processing, az online
analitikai feldolgozás. A kilencvenes évek elején erősödött fel az igény az
elemző, analitikai alkalmazások iránt, és ezzel együtt egy egységes
módszertan és követelményrendszer felállítására. 1992-ben megjelent E.F.Codd
cikke, melyben bevezeti az OLAP fogalmát, és 12 pontban definiál egy általa
felállított követelményrendszert. Ez a definíció az online analitikai
rendszerekre az idők során általánosan elfogadottá vált. |
||||||||||||||||||||||||||||||||||||||||||||||
|
Codd OLAP szabályai:
|
||||||||||||||||||||||||||||||||||||||||||||||
|
Sajnos az is nyilvánvaló azonban, hogy
Codd definíciója iránymutató ugyan, de ugyanakkor elég pontatlan.
Különböző OLAP alkalmazás szállítók gyakran értelmezik különbözőképp Codd
pontjait. Annyi azonban biztos, hogy az OLAP mindig magában foglalja adatok
interaktív lekérdezését, melyet az adatok analízise követ. Központi fogalma
az adatok multidimenzionális nézete, amire még részletesen kitérünk. |
||||||||||||||||||||||||||||||||||||||||||||||
5.3. OLTP - OLAP renszerek összehasonlítása |
||||||||||||||||||||||||||||||||||||||||||||||
|
Szokás összehasonlítani az OLTP és OLAP alkalmazások tulajdonságait. Ezt megtesszük mi is, ld. ábra. Jól látszanak a követelmények közti különbségek. Mostanra általánosan elfogadottá vált az a nézet, miszerint a két rendszer különbözik annyira céljaiban, felhasználóiban, módszereiben, hogy érdemes az online elemző alkalmazásokat és rendszereket teljesen külön, független rendszerként megvalósítani. |
||||||||||||||||||||||||||||||||||||||||||||||
|
||||||||||||||||||||||||||||||||||||||||||||||
|
2.ábra: OLTP és OLAP rendszerek összehasonlítása |
||||||||||||||||||||||||||||||||||||||||||||||
| A
tranzakciós rendszerekre közvetlenül épített analitikai alkalmazásoknál
problémát jelenthet az analízisek nem gyakori, de hatalmas adatigénye, amely
veszélybe sodorhatja az OLTP feltétlen megkövetelt megbízhatóságát,
gyorsaságát. Ne felejtsük el azonban, hogy az OLAP alkalmazások a különbözőségük ellenére szorosan kapcsolódnak OLTP alkalmazásokhoz, hiszen az OLAP alkalmazások adataikat (speciálisan csak az elemzés céljával) valamilyen meglévő OLTP rendszertől, operatív adatbázisból nyerik. A különbségek miatt viszont adattárház építésekor a meglévő OLTP rendszerünket nem éri meg OLAP elemzésekkel és alkalmazásokkal terhelni, erre célszerű külön adatbázist, adattárházat fenntartani. Egy gyakran hangoztatott nézőpont szerint az OLTP rendszerekre adatok tárolásának célja (putting data in) jellemző, ezzel szemben az OLAP rendszerek fő célja az adatkinyerés (getting data out). |
||||||||||||||||||||||||||||||||||||||||||||||
|
||||||||||||||||||||||||||||||||||||||||||||||
| 6.1. Adatsémák a tranzakciófeldolgozó rendszerektől az OLAP alkalmazásokig | ||||||||||||||||||||||||||||||||||||||||||||||
|
Az adatmodell kifejezést most a következő értelemben fogjuk
használni: az adatmodell olyan fogalmak halmaza, melyek az adatbázis struktúrájának
leírására használhatóak.
A következőkben áttekintjük az adattárházzal kapcsolatos
adatmodellezési módszereket. |
||||||||||||||||||||||||||||||||||||||||||||||
|
|
||||||||||||||||||||||||||||||||||||||||||||||
|
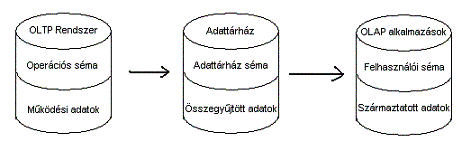
5.ábra: Adattárház: tároló a tranzakciós és OLAP feldolgozás között |
||||||||||||||||||||||||||||||||||||||||||||||
|
Az ábrán az OLTP és OLAP rendszerek implementációja során felhasznált adatmodellek láthatóak áttekintő jelleggel. Mi részletesen most az OLAP megoldások adatmodelljeivel foglalkozunk. A szaggatott vonalak jelzik az előzőekben felvázolt kategóriahatárokat. |
||||||||||||||||||||||||||||||||||||||||||||||
|
|
||||||||||||||||||||||||||||||||||||||||||||||
|
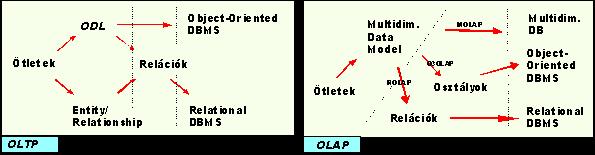
6.ábra: Adatmodellezés rétegei |
||||||||||||||||||||||||||||||||||||||||||||||
|
6.2. Tranzakciós rendszerek adatmodelljei - operációs séma |
||||||||||||||||||||||||||||||||||||||||||||||
|
Az OLTP rendszerek nagy múltra tekintenek vissza, ennek megfelelően jól bevált modellrendszerekkel és jól kidolgozott eméleti háttérrel dicsekedhetnek (ez sajnos az adattárházakra még nem mondható el tiszta szívvel). A legelterjedtebb módszer a tárolandó objektumok leírására az Egyed/Kapcsolat diagramm (Entity/Relationship Diagram) ami aztán könnyen transzponálható az adatbázis relációs adatmodelljébe. |
||||||||||||||||||||||||||||||||||||||||||||||
|
6.3. Szemantikai réteg - felhasználói multidimenzionális adatfogalom |
||||||||||||||||||||||||||||||||||||||||||||||
|
Ebben a pontban az adattárház felhasználóinak fogalmi, elméleti (conceptual) adatmodelljét tekintjük át. Egy adattárház felhasználói általában nem elsősorban informatikusok, informatikai, matematikai felkészültségük sem feltétlenül mély. A felhasználóknak éppen ezért biztosítani kell egy könnyen kezelhető, rugalmas felületet, mellyel anélkül, hogy technikai részletekben kellene elmerülniük, tetszőlegesen lekérdezhetik, elemezhetik adataikat. Ehhez biztosít egy általánosan elfogadott adatabsztrakciós módszert a multidimenzionális modell. (OLAP eszközök esetén a multidimenzionális modell követelmény.) Meg kell jegyeznünk, hogy a multidimenzionális modell fogalomkészlete erősen intuitív, általában nem definiálják absztrakt módszerekkel. |
||||||||||||||||||||||||||||||||||||||||||||||
6.3.1. Alapfogalmak |
||||||||||||||||||||||||||||||||||||||||||||||
|
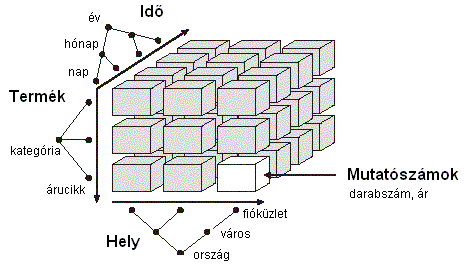
Tényadatnak (v. mutatószámnak,
keyfigure, Kennzahl)
nevezzük azokat mérhető, numerikus adatokat, melyeket elemezni és ehhez
tárolni szeretnénk. (A koncepcionális modellben inkább mutatószám, későbbi
adatbázis realizációknál inkább tény, tényadat néven szerepel.) Lehetnek hagyományos, vagy a közgazdaságtanból átvett
mérőszámok. Ilyenek pl. az árbevétel, súly, eladott darabszám, nyereség,
raktárkészlet, stb. A tényadatok általában additívak (pl. árbevétel), de
lehetnek részben additívak vagy nem additívak is (pl. haszonkulcs). |
||||||||||||||||||||||||||||||||||||||||||||||
|
|
||||||||||||||||||||||||||||||||||||||||||||||
|
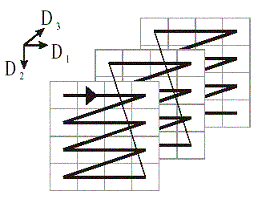
7.ábra: Eladási adatok háromdimenziós adatkockája |
||||||||||||||||||||||||||||||||||||||||||||||
6.3.2. Az adatkockák megjelenítése, kezelése a felhasználói felületen |
||||||||||||||||||||||||||||||||||||||||||||||
|
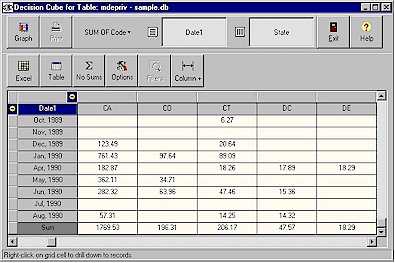
Nyilvánvaló, hogy az adatkockánkat, hacsak nem 2 (esetleg 3) dimenziós, nem tudjuk megfelelően megjeleníteni a végfelhasználó számára. Az elemző, a felhasználó az adatkockának mindig csak egy megfelelő két dimenziós nézetét látja, láthatja, egy táblázat formájában. Jelenti ez azt, hogy a többi dimenzió szerint az adatok vagy fel lesznek összegezve, vagy egy konkrét értékre le lesznek szűrve a megjelenítéshez. |
||||||||||||||||||||||||||||||||||||||||||||||
|
|
||||||||||||||||||||||||||||||||||||||||||||||
|
8.ábra: Példa riportozó OLAP felüleletre |
||||||||||||||||||||||||||||||||||||||||||||||
6.3.3. Analízisoperátorok |
||||||||||||||||||||||||||||||||||||||||||||||
|
Az adatkockákon végzett elemzésekhez kockák közti műveleteket használhatunk. Most megnézzük a leginkább elterjedt műveleteket. Ezek a műveletek az adatkockához egy új adatkockát rendelnek, céljuk általában az, hogy az új adatkocka az adatok egy olyan nézetét biztosítsa, ami az elemzési szempontunknak megfelel, esetleg táblázatként meg is jeleníthető.
Fontos, hogy ezen műveletek elvégzésére a felhasználók másodperces nagyságrendű válaszidőket várnak. Általában 5 másodperc körülienek határozzák meg a még elfogadható OLAP műveleti időket! |
||||||||||||||||||||||||||||||||||||||||||||||
6.3.4. A modell formalizált leírása |
||||||||||||||||||||||||||||||||||||||||||||||
|
A hagyományos adatbázis leírási módszereink (Entity/Relationship, UML) a multidimenzionális rendszer esetében nem használhatók megfelelően, vagy nem nyújtanak hasznos segédeszközt. Kénytelenek vagyunk lemondani az általánosan használhatóságról, hogy használható multidimenzionális leíró rendszert kapjunk. Itt most két ilyen formális leíró módszert nézünk meg. |
||||||||||||||||||||||||||||||||||||||||||||||
|
ME/R modell:
Multidimensional Entity/ Relationship Modell |
||||||||||||||||||||||||||||||||||||||||||||||
|
|
||||||||||||||||||||||||||||||||||||||||||||||
|
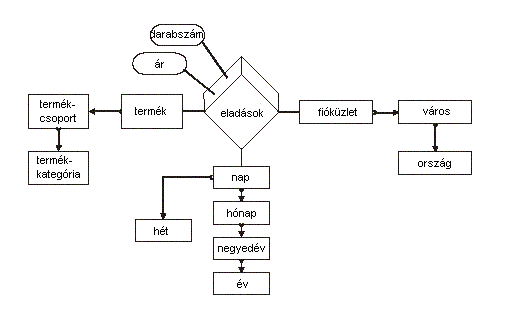
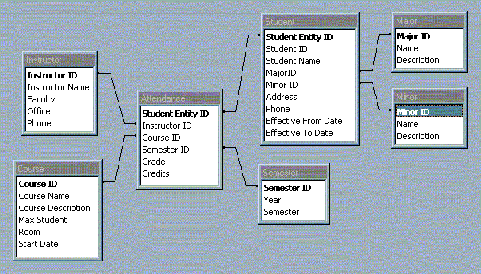
9.ábra: ME/R Modell példa |
||||||||||||||||||||||||||||||||||||||||||||||
| ADAPT:
Application Design for Analitical Processing Technologies |
||||||||||||||||||||||||||||||||||||||||||||||
|
6.4. Logikai réteg - adatbázis (belső) sémák |
||||||||||||||||||||||||||||||||||||||||||||||
|
Célunk az előzőekben részletezett elvi multidimenzionális
adatmodell megvalósítása adatbázis belső sémák szintjén. Itt már különbséget kell
tennünk a sémák közt megvalósítás módja szerint, vagyis, hogy milyen
adatbázisban szeretnénk tárolni az adatokat. A csoportok ezek szerint: |
||||||||||||||||||||||||||||||||||||||||||||||
|
|
||||||||||||||||||||||||||||||||||||||||||||||
|
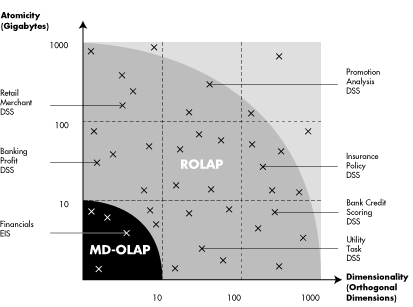
10.ábra: ROLAP-MOLAP rugalmasság összehasonlítás konkrét alkalmazásokkal |
||||||||||||||||||||||||||||||||||||||||||||||
|
||||||||||||||||||||||||||||||||||||||||||||||
| Multidimenzionális OLAP alkalmazások esetében adatainkat speciális multidimenzionális struktúrában tároljuk. | ||||||||||||||||||||||||||||||||||||||||||||||
7.1. Adatstruktúrák |
||||||||||||||||||||||||||||||||||||||||||||||
|
MOLAP esetén külön kezeljük a dimenziók adatait és a
tényadatokat. |
||||||||||||||||||||||||||||||||||||||||||||||
|
|
||||||||||||||||||||||||||||||||||||||||||||||
|
11.ábra: Hierarchia MOLAP megoldása három dimenzió esetén |
||||||||||||||||||||||||||||||||||||||||||||||
|
Aggregált adatok: Aggregált,
felösszegzett adatok kezelése MOLAP architektúra esetén akkor sem jár
elfogadhatatlan válaszidővel, ha külön nem foglalkozunk összegek
tárolásával, mégpedig a gyors adatelérés miatt. Ezen
túlmenően előre is definiálhatunk a kockákban aggregációs szinteket, hasonlóképp
mint a hierarchiák esetében, ekkor az összegek beépülnek a kockába. Fontos
megjegyezni a rendszerek azon hiányosságát, hogy nem lehet aggregált
adatokat tárolni dimenziók nem teljes értékkészletével. Például nem
megoldható, hogy aggregált adatokat tároljunk csak Gödöllő és Eger
adataival. Igaz ugyanakkor az is, hogy a felhasználói lekérdezések ritkán
ilyen jellegűek. |
||||||||||||||||||||||||||||||||||||||||||||||
7.2. A többdimenziós tömb tárolás |
||||||||||||||||||||||||||||||||||||||||||||||
|
A kocka indexeléséhez szokás olyan indexstruktúrát
használni, ahol a kocka celláit valamilyen adott algoritmussal
sorbarendezzük, majd az indexek sora ennek a sorbarendezésnek felel meg.
Ennek legegyszerűbb módja, ha a kocka adott (x1, x2, .. xn) koordinátájú
pontjához a kordinátákból alkotott x1 + (x2-1)*|{1.dimenzió
elemszáma}|+...+(xn-1)*|{(n-1)..dimenzió elemszáma}| sorszámú indexet
rendeljük. |
||||||||||||||||||||||||||||||||||||||||||||||
|
|
||||||||||||||||||||||||||||||||||||||||||||||
|
12.ábra: Háromdimenziós kocka celláinak egy rendezése |
||||||||||||||||||||||||||||||||||||||||||||||
7.3. Ritka mátrix kezelés |
||||||||||||||||||||||||||||||||||||||||||||||
|
Amennyiben az adatmátrixunk ritka, tehát az adatok a kockán belül szétszórtan helyezkednek el, a kocka a hasznos adat mennyiségéhez képest nagy területet foglalhat el. Ennek oka, hogy az előre felépített indexstruktúra miatt a háttértáron előre helyet kell foglalni a kocka egészének. Sok dimenzió és nagy kiterjedésű dimenziók esetén ez akár oda is vezethet, hogy az adatbázis használhatatlanul naggyá válik. (A konkrét adatok egy becsléséhez ld. 6.ábra.) A ritka mátrix probléma kezelésére egyes multidimenzionális adatbáziskezelők tartalmaznak ún. ritka mátrix algoritmust, amely a kocka szerkezetéből megpróbálja a nem használt részeket kiszűrni, és a nekik fenntartott helyet felszabadítani, így elkerülve a mátrix kezelhetetlen naggyá válását. |
||||||||||||||||||||||||||||||||||||||||||||||
7.4. A multidimenzionális tárolás korlátai |
||||||||||||||||||||||||||||||||||||||||||||||
|
A már említett ritka mátrix probléma mellett meg kell említenünk még, hogy a strukturális változtatások ebben a modellben rendkívül költségesek. Emellett ezek a rendszerek általában nehezen skálázhatók, nincs általánosan elfogadott szabványuk, minden gyártó saját utakon jár. |
||||||||||||||||||||||||||||||||||||||||||||||
7.5. MOLAP termékek |
||||||||||||||||||||||||||||||||||||||||||||||
|
A MOLAP termékek széles skálán mozognak az asztali, néhány 10 Mb mennyiségű adat kezelésére alkalmas alkalmazásoktól kezdve a vállalati "high end" szoftverekig. Az első csoportba tartoznak pl. a Cognos PowerPlay-e, az Andyne PaBLO-ja és a Business Objects Mercury-ja. Az utóbbi kategóriában a Kenan Acumulata ES-e, az Oracle Express családja, a Planning Sciences Gentium-a és a Holistic System Holos-a olyan termékek, melyek nem csupán a multidimenzionális adattárolást, hanem rengeteg más kapcsolódó feladatot is megoldanak. Tisztán multidimenzionális adatbázis motorok az Arbor Essbase-e, a D&B/Pilot Ship Servere és a TM/1 a Sinper-től. |
||||||||||||||||||||||||||||||||||||||||||||||
|
||||||||||||||||||||||||||||||||||||||||||||||
|
ROLAP architektúra esetén tehát a
koncepcionális modellünket a hagyományos relációs adatbázis környezetben szeretnénk megvalósítani.
(Feltételezem, hogy alapvető relációs-adatbázis ismeretekkel rendelkezünk.) |
||||||||||||||||||||||||||||||||||||||||||||||
8.1. Relációs adattárház séma tervezésének 4 lépéses folyamata |
||||||||||||||||||||||||||||||||||||||||||||||
|
Nézzük meg a Kimball által [2.] javasolt négylépcsős relációs adattárház-tervezési metódust!
A lépésekkel előre haladva előfordulhat, hogy előző lépésre visszatérve már meghatározott jellemzőket újra kell gondolnunk, kiegészítenünk, módosítanunk kell. |
||||||||||||||||||||||||||||||||||||||||||||||
8.2. Csillagséma (star schema) |
||||||||||||||||||||||||||||||||||||||||||||||
|
Modellünkben a tényadatok, mutatószámok játsszák a központi szerepet. A koncepciónknak megfelelően készítünk egy táblát, amely tartalmazza az összes tényadatunkat, és azok jellemzőit. A ténytábla normalizálásaként a mutatószámok jellemzőit dimenziók szerint egy-egy dimenziótáblában gyűjtjük össze, melynek minden elemét egy kulcs azonosít. Célszerű generált kulcsot használni, melyek nem rendelkeznek önálló információtartalommal, viszont az adatbáziskezelő támogatja a kezelését. |
||||||||||||||||||||||||||||||||||||||||||||||
|
|
||||||||||||||||||||||||||||||||||||||||||||||
|
13.ábra: Termék dimenzió dimenziótáblája (példa) |
||||||||||||||||||||||||||||||||||||||||||||||
|
|
||||||||||||||||||||||||||||||||||||||||||||||
|
|
||||||||||||||||||||||||||||||||||||||||||||||
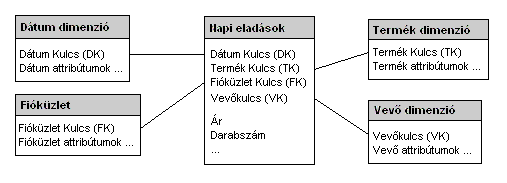
|
14.ábra: Csillagséma: "Napi eladások" adatkocka megvalósítása |
||||||||||||||||||||||||||||||||||||||||||||||
A csillagséma előnyei:
A csillagséma hátrányai:
|
||||||||||||||||||||||||||||||||||||||||||||||
8.3. Hópehely séma (snowflake scheme) |
||||||||||||||||||||||||||||||||||||||||||||||
|
A hópehely séma nagyban hasonlít a csillag sémára, csak itt normalizáljuk a dimenziótáblákat (megszüntetjük vagy csökkentjük a redundanciát). |
||||||||||||||||||||||||||||||||||||||||||||||
|
|
||||||||||||||||||||||||||||||||||||||||||||||
|
15.ábra: Példa hópehely sémára |
||||||||||||||||||||||||||||||||||||||||||||||
| 8.4. Konszolidált csillagséma | ||||||||||||||||||||||||||||||||||||||||||||||
|
Konszolidált csillagsémának hívjuk azt a speciális csillagsémát, mikor a központi ténytáblában aggregált adatokat is tárolunk. |
||||||||||||||||||||||||||||||||||||||||||||||
8.7. ROLAP teljesítmény javítása |
||||||||||||||||||||||||||||||||||||||||||||||
|
A relációs multidimenzionális eszközök teljesítményében (válaszidőkben) általában elmaradnak a MOLAP eszközöktől. A teljesítmény javítására három standard módszert alkalmaznak Nem térünk ki most a relációs adatbáziskezelők teljesítményének javítására, amely tetemes elméleti és gyakorlati háttérrel büszkélkedhet. A következő módszerek már csak ezeket kiegészítő, speciálisan csak adattárházakra alkalmazható módszerek. |
||||||||||||||||||||||||||||||||||||||||||||||
8.7.1. Denormalizáció |
||||||||||||||||||||||||||||||||||||||||||||||
|
Denormalizáció alatt értjük azt az eljárást, mikor a
ténytáblában redundánsan eltárolunk járulékos jellemzőket, olyanokat, melyek
a dimenziótáblákban egyébként szerepelnek. Például, a kiskereskedős példánál
az elemzéseknél gyakran használják a termék dimenziót, de abból csak a
gyártó jellemzőt. Ekkor, ha a válaszidők nem megfelelőek, a ténytáblába mint
oszlop bevesszük a "gyártó" jellemzőt, így megspórolva egy join műveletet a
kiértékelésnél, elbukva viszont tárterületet a redundancia miatt. |
||||||||||||||||||||||||||||||||||||||||||||||
8.7.2. Aggregáció |
||||||||||||||||||||||||||||||||||||||||||||||
|
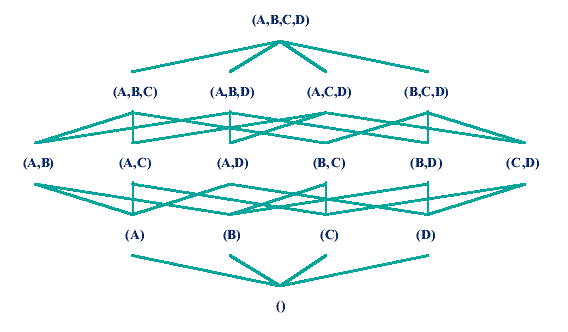
Aggregáció alatt értjük azt, mikor az adatok valamely szempont szerinti felösszegzett változatát is eltároljuk az adatbázisunkban. Ez jelentheti egy vagy több dimenzió elhagyását. A következő ábra szemlélteti egy négydimenziós adatkocka agregációs lehetőségeit. Nyilván az aggregációs szintek bevezetésével, használatával a válaszidők jelentősen javulhatnak egyes lekérdezéseknél, igaz viszont az is, hogy az összegeket minden új adatelem beszúrásánál frissíteni kell. |
||||||||||||||||||||||||||||||||||||||||||||||
|
|
||||||||||||||||||||||||||||||||||||||||||||||
|
18.ábra: Aggregációs rács |
||||||||||||||||||||||||||||||||||||||||||||||
|
Ezek közül a
lehetőségek közül érdemes kiválasztani a leginkább használt nézeteket. |
||||||||||||||||||||||||||||||||||||||||||||||
8.7.3. Particionálás |
||||||||||||||||||||||||||||||||||||||||||||||
|
A ténytábla túl nagyra hízása a teljesítmény rovására megy. Ezt elkerülendő szokás a táblát több ténytáblára vágni, melyek esetleg akár párhuzamosan is feldolgozhatók lehetnek. |
||||||||||||||||||||||||||||||||||||||||||||||
|
||||||||||||||||||||||||||||||||||||||||||||||
|
Egyre jellemzőbb trend, hogy a már meglévő relációs
adatbázisok funkcionalitását kibővítik multidimenzionális tárolási
lehetőségekkel. Ez lehetőséget ad olyan hibrid architektúrák felépítésére,
melyeket alapvetően relációs módszerekkel építünk annak jól skálázható és
robosztus tulajdonságai miatt, de kiegészítésként a gyakran használt
nézetekre, adatokra építünk multidimenzionális kockákat is, a jóval gyorsabb
lekérdezési sebesség miatt. |
||||||||||||||||||||||||||||||||||||||||||||||
|
||||||||||||||||||||||||||||||||||||||||||||||
|
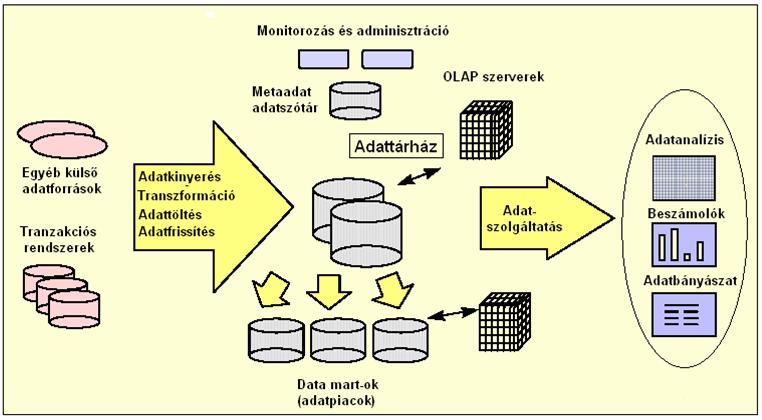
Az adattárház-rendszer működtetéséhez, az információfeldolgozás automatizálásához és adminisztrációjához sok eszközre, komponensre van szükségünk. Ezek az eszközök a data warehousing folyamatának egy-egy kisebb-nagyobb részfolyamatára nyújtanak megoldást, kézenfekvő tehát őket a megoldott részfeladatok alapján csoportokba sorolni. Az ábrán szerepelnek az adattárház alapvető komponensei. |
||||||||||||||||||||||||||||||||||||||||||||||
|
|
||||||||||||||||||||||||||||||||||||||||||||||
|
19.ábra: Adattárház komponensek |
||||||||||||||||||||||||||||||||||||||||||||||
10.1. Az adatok kinyerése és betöltése az adattárházba - Data Staging Area |
||||||||||||||||||||||||||||||||||||||||||||||
|
ETL Tools: Extraction, Transformation and Load, vagyis olyan
eszközök, melyek az adatok kinyerését, transzformációját és adattárházba
töltését támogatják. Ez a csoport jelenti az összekötő kapcsot a
tranzakciós rendszerek és az adattárház között.
Az adattárház adatai az operatív adatokból származnak,
az operatív adatok változásainak propagálódniuk kell az adattárház
részletezett és aggregált adatain át a felhasználó által látható
beszámolókig. Nem feltétlenül igaz viszont, hogy az operatív adatok változásait
ezek azonnal
követik. Fontos az adatfeltöltés periodicitásának és időpontjának gondos
megválasztása. A túl gyakori adatfrissítés az operatív rendszerek
fölöslegesen nagy terheléséhez vezethet, a túl ritka frissítésnek pedig az
elemzett adatok naprakészsége láthatja kárát. Szétválaszthatjuk az
adatainkat eszerint pl. óránkénti, naponkénti, hetenkénti és havonkénti
adatfrissítést igénylő adatokra, és ezeknek megfelelően időzíthetjük az adattöltést az operatív
rendszerek számára leginkább megfelelő időpontokra. Gyakran ezek az
időpontok, időintervallumok éjszakai órák, hétvégék, ekkor legkisebb
ugyanis az OLTP rendszerek terhelése. Fontos odafigyelni arra, hogy adott
adattárház tárgyterületek adattöltése nagy adatmozgásokat igényelhet, az
OLTP rendszerek hagyományos felhasználásával szemben több ezer, millió
rekord egyidejű lekérdezésével jár, melyek semmiképp nem veszélyeztethetik a vállalat
mindennapi működését.
Két újabb kategóriát jelenthet az adattöltések
megkülönböztetése a változások követésének szemszögéből. Eszerint, ha az
operatív rendszerben új vagy megváltozott adatokra vonatkozóan csak a
változás valamilyen leírását továbbítjuk, delta-töltésről (a
változásra utalva), ha az operatív rendszer adatait egy az egyben
továbbítjuk, teljes-töltésről beszélhetünk. |
||||||||||||||||||||||||||||||||||||||||||||||
10.2. Adatszolgáltatás az alkalmazások felé (OLAP Tools) - Data Presentation Area |
||||||||||||||||||||||||||||||||||||||||||||||
|
Ide az adattárház adatain OLAP lekérdezéseket lehetővé tévő eszközök
tartoznak. Az adattárház valamelyik már tárgyalt módszerrel tárolja az
analitikai adatokat, az adatkockákat, ezek az eszközök pedig ezekhez az
adatokhoz biztosítanak az OLAP elvárásoknak megfelelő lekérdező felületet.
Ezek az adatszolgáltató megoldások túllépnek a hagyományos adatbázis
lekérdezéseket kiszolgáló SQL szerverek funkcionalitásán, speciális OLAP lekérdezésekre,
lekérdezés sorozatokat is
támogatva. |
||||||||||||||||||||||||||||||||||||||||||||||
10.3. Alkalmazások |
||||||||||||||||||||||||||||||||||||||||||||||
|
Ez a csoport az adattárház adataira épülő elemző, riportozó alkalmazásokat foglalja magába. Nagyon széles skálán mozoghatnak ezek az eszközök, kezdve a legegyszerűbb lekérdező-beszámolókészítő alkalmazásoktól a hagyományos statisztikai elemző-szoftvereken át az adatbányász eszközökig. Gyakran találkozhatunk valamely már ismert elemző eszköz vagy táblázatkezelő (SAP esetében pl. Excel) OLAP funkciókkal kibővített változatával. Ennek előnye a gyors tanulhatóság és a megszokott környezet, ezáltal a végfelhasználókkal való könnyebb elfogadtathatóság. |
||||||||||||||||||||||||||||||||||||||||||||||
10.4.. Felügyelet, adminisztráció és metaadat-kezelés |
||||||||||||||||||||||||||||||||||||||||||||||
|
Metaadat: Ebben az esetben a "meta-" előtagot olyan értelemben használjuk, mint egy átfogó jelző olyan fogalom-és leíró módszerekre, amelyek egy eredeti fogalomrendszerrel foglalkoznak, abból származnak. Innen adódik a metaadat kifejezésre az "adatokat leíró adatok" meghatározás. A metaadat fogalma már a '60-as évektől kezdve jelen van az informatikában, a nem szekvenciális file-manager rendszerek adatleíró mezőitől kezdve (metaadatként felfogva az adatrekordok indexeléséhez felhasznált rekord-leíró mezőket) mind sokrétűbb módszerekként. A '70-es évektől relációs adatbáziskezelő rendszereknél is megjelent és kifejlődött többféle adatdefiníciós módszer, adatleíró megoldás, a tábladefiníciós megoldásoktól kezdve absztraktabb módszerekig, mint pl. az Entity/Relationship modell. sok szállító --> sok tervezést és adminisztrációt segítő termék --> sok
metaadat-kezelő megoldás |
||||||||||||||||||||||||||||||||||||||||||||||
|
||||||||||||||||||||||||||||||||||||||||||||||
|
||||||||||||||||||||||||||||||||||||||||||||||
| A következőkben a teljesség igénye nélkül kiragadok néhány, számora érdekesnek, valamint időszerűnek tűnő kutatási területet az adattárházak területéről. | ||||||||||||||||||||||||||||||||||||||||||||||
| 12.1. Aggregáció |
||||||||||||||||||||||||||||||||||||||||||||||
|
A relációs adattárházak gyenge pontja a lekérdezések viszonylag nagy válaszideje főképp az elvégzendő tábla-összekapcsolások (join) miatt. Erre megoldást jelenthet megfelelően kialakított aggregátumok (technológiai elnevezésével élve materializált nézetek) tárolása az adatbázisban. Kérdéses viszont, hogy milyen algoritmussal érdemes kiválasztani az lehetséges aggregátumokból a megfelelőket, milyen hierarchikus szerkezetet érdemes belőlük kialakítani, és milyen módszerrel lehet az aggregátumokat saját magukat karbantartó tulajdonsággal felruházni. |
||||||||||||||||||||||||||||||||||||||||||||||
| 12.2. Indexek |
||||||||||||||||||||||||||||||||||||||||||||||
|
A relációs tárolás hatékonyságát, a lekérdezések válaszidejét nagyban javíthatja megfelelő indexstruktúrák alkalmazása. Kutatás tárgyát képezi az adattárházak struktúráival hatékony módon működő indexelési módszerek kialakítása. Két már bevált és hasznos ilyen jellegű index-típus az úgynevezett bitmap index, valamint a join index. Az indexelés témaköre nagyban összefügg az előző pontban tárgyalt aggregátum-kezelés témakörrel: mindkét témakör olyan, adatbázisban járulékosan tárolt, redundáns adatok kezelésével, kialakításával foglalkozik, melynek célja a lekérdezések válaszideinek csökkentése. |
||||||||||||||||||||||||||||||||||||||||||||||
| 12.3. Induktív adatbázisok |
||||||||||||||||||||||||||||||||||||||||||||||
|
Induktív adatbázis alatt értjük azokat az adatbázisokat, melyek nem csak adatokat, hanem az adatokat leíró következtetési sémákat is tartalmaznak. Az induktív adatbázisok koncepciója még nem teljesen kiforrott, annyit azonban leszögezhetünk, hogy induktív következtetési szabályokat, modelleket járulékosan tartalmazó adatbázisokról van szó. Képzeljünk el például egy olyan adatbázist, amely amellet, hogy tartalmazza például egy vállalat teljes vevőnyilvántartását, és lehetővé teszi a (deduktív következtetésekként felfogható) hagyományos adatbázis lekérdezések végrehajtását, olyan modelleket is tartalmaz, melyek az adathalmazból általánosított következtetéseket tartalmaznak, például jellemző megrendelési szokásokat, a vevők klaszterezését stb. Az induktív adatbázisok témaköre szoros kapcsolatban áll az adatbányászattal, ahol is hasonló rejtett összefüggések kinyerése a cél. |
||||||||||||||||||||||||||||||||||||||||||||||
| 12.4. Lekérdezés optimalizálás |
||||||||||||||||||||||||||||||||||||||||||||||
|
A relációs adattárházak csillag struktúrájának lekérdezését célzó query-k gyakran nem az optimális, leggyorsabban kiértékelhető formában érkeznek. Kérdés, hogy hogyan lehet a query-ket az optimális formára alakítani, és a lehető leggyorsabban kiszolgálni? |
||||||||||||||||||||||||||||||||||||||||||||||
| 12.5. SQL bővítés |
||||||||||||||||||||||||||||||||||||||||||||||
|
Az SQL lekérdező nyelv nem nyújt megfelelő támogatást OLAP, illetve adatbányász lekérdezések végrehajtásához. Kérdés, hogy milyen bővítés lenne célravezető ezek magasszintű támogatásához? |
||||||||||||||||||||||||||||||||||||||||||||||
| 12.6. Formális adatmodellek |
||||||||||||||||||||||||||||||||||||||||||||||
|
Az adattárházak adatmodelljei még korántsem mutatnak egységes, kiforrott képet. A tervezés, az implementáció és a használat során megfelelően használható, elfogadott modell még nincs jelen. |
||||||||||||||||||||||||||||||||||||||||||||||
| 12.7. Elosztott adattárházak |
||||||||||||||||||||||||||||||||||||||||||||||
|
Adattárházat építeni PC-k klasztereiből, vagy általában sok független adatpiacból még nem kidolgozott, de ígéretes terület. A megfelelő módszerek, modellek még hiányoznak. |
||||||||||||||||||||||||||||||||||||||||||||||
| 12.8. Metaadat kezelés |
||||||||||||||||||||||||||||||||||||||||||||||
|
Az adattárház metaadat-szótára kulcsfontosságú a használhatósága és a hatékonysága szempontjából. Fontos ezért, hogy kialakításuk jól átgondoltan, esetleg megfelelő formalizmusok használatával történjen. Fontos még az általános használhatóság, a könnyen illeszthetőség feltétele is más rendszerekhez, valamint lehetőség szerint a minél teljesebb elfogadottság, a nagy piaci szereplők meggyőzése a metaadatkezelő szabvány használatáról, így az egységesítés. |
||||||||||||||||||||||||||||||||||||||||||||||
| 12.9. Weblog-elemző Clickstream adattárházak |
||||||||||||||||||||||||||||||||||||||||||||||
|
A különböző portálok, vállalati webszerverek egyre nagyobb felhasználása megteremtette az igényt az általuk készített naplófile-ok megfelelő analízisére. Erre megfelelő megoldást nyújthat egy adattárház, azonban a rendkívül nagy adatmennnyiségek miatt a megvalósított struktúrák, megoldások gyakran kudarchoz vezetnek. Ezek kutatása is ígéretes terület. | ||||||||||||||||||||||||||||||||||||||||||||||
|
||||||||||||||||||||||||||||||||||||||||||||||
|
Egy régi, de tanulságos statisztika található a következő URL-en: http://www.esj.com/Departments/article.asp?EditorialsID=51 |
||||||||||||||||||||||||||||||||||||||||||||||
|
||||||||||||||||||||||||||||||||||||||||||||||
|
[1] W.H.Inmon: Building the Data Warehouse - Second Edition [2] Ralph Kimball, Margy Ross: The Data Warehouse Toolkit - Second Edition [3] Naeem Hashmi: Businness Information Warehouse for SAP [4] Andreas Totok: Modellierung von OLAP- und Data-Warehouse-Systemen [5] Gary Dodge, Tim Gorman: Essential Oracle8i Data Warehousing [6] Matthias Jarke, Maurizio Lenzerini, Yannis Vassiliou, Panod Vassiliadis: Fundamentals of Data Warehouses [7] Sakhr Youness: Professional Data Warehousing with SQL Server 7.0 and OLAP Services [8] Wolfgang Martin: Data Warehousing: Data Mining - OLAP [9] Schutte, Rotthowe, Holten: Data Warehouse Management-handbuch [10] Ramon Baraquin, Herb Edelstein: Planning and Designing the Data Warehouse |
||||||||||||||||||||||||||||||||||||||||||||||